Data Lake é um reservatório de dados para integração, armazenamento e Analytics, seu conceito é mais amplo que um Data Warehouse, pois aceita dados não estruturados e semi estruturados. Abaixo falaremos um pouco mais sobre esse novo conceito de estrutura de dados para ambientes analíticos.
História do Data Lake
A primeira citação sobre o Data Lake foi do blog do James Dixon onde ele descreve problemas em relação aos dados que estavam sendo encontrados naquele momento :
https://jamesdixon.wordpress.com/2010/10/14/pentaho-hadoop-and-data-lakes/
Abaixo o Texto descrito por ele
Earlier this week, at Hadoop World in New York, Pentaho announced availability of our first Hadoop release.
As part of the initial research into the Hadoop arena I talked to many companies that use Hadoop. Several common attributes and themes emerged from these meetings:
- 80-90% of companies are dealing with structured or semi-structured data (not unstructured).
- The source of the data is typically a single application or system.
- The data is typically sub-transactional or non-transactional.
- There are some known questions to ask of the data.
- There are many unknown questions that will arise in the future.
- There are multiple user communities that have questions of the data.
- The data is of a scale or daily volume such that it won’t fit technically and/or economically into an RDBMS.
In the past the standard way to handle reporting and analysis of this data was to identify the most interesting attributes, and to aggregate these into a data mart. There are several problems with this approach:
- Only a subset of the attributes are examined, so only pre-determined questions can be answered.
- The data is aggregated so visibility into the lowest levels is lost
Based on the requirements above and the problems of the traditional solutions we have created a concept called the Data Lake to describe an optimal solution.
If you think of a datamart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.
For more information on this concept you can watch a presentation on it here: Pentaho’s Big Data Architecture
O conceito fica claro com a comparação :
“Data Mart são como pacotes de garrafas de água – limpas, empacotadas e estruturadas para consumo fácil ”
“Data Lake é um grande armazenador de água em estado natural, várias fontes alimentam o lago, vários usuários podem vir para examinar, mergulhar ou pegar amostras de dados”
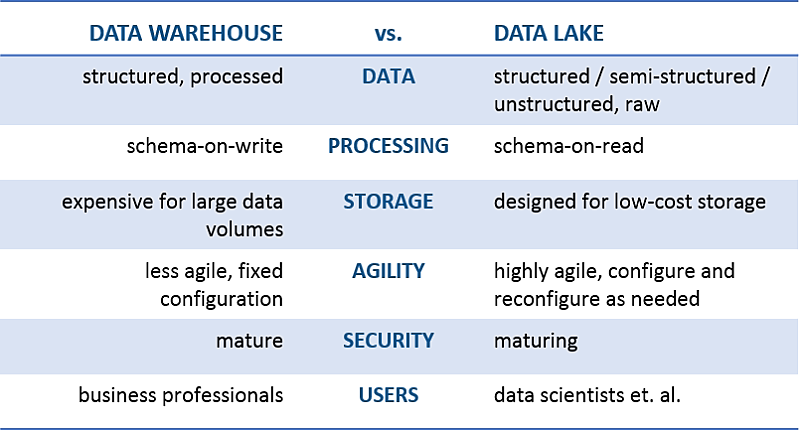
Data Lake vs Data Warehouses
Depois no KDNuggets, um artigo muito interessante descreveu as principais diferenças entre o Data Lake e os Data Warehouses :
https://www.kdnuggets.com/2015/09/data-lake-vs-data-warehouse-key-differences.html
 DATA LAKE ON PREMISES
DATA LAKE ON PREMISES
 DATA LAKE ON PREMISES
DATA LAKE ON PREMISESNo Data Lake On premisses os softwares são instalados em máquinas próprias ou hospedadas em Data Center, geralmente se utiliza Hadoop para essa abordagem de Data Lake, visto que o Hadoop é a opção mais completa de software.
Atualmente o Data Lake on Premises deve ser bem avaliado, pois os custos de montagem da infra estrutura são bem pesados, devemos considerar : servidores, networking, instalação, update, e tudo que cerca a colocação de um servidor no ar : energia e resfriamento.
DATA LAKE CLOUD
Quando criado na nuvem, o Data Lake Cloud, tem sua infra estrutura fica sob responsabilidade de um provedor de Cloud ( AWS, GCP, Azure, por exemplo ), que é responsável por prover todos os softwares e serviços para o Lake funcionar.
Todos os provedores atualmente tem soluções para Data Lake, seja ela baseada em serviços próprios ou mesmo fazendo a hospedagem de máquinas com o Hadoop ou outra estrutura de Big Data.
DATA LAKE AZURE
No texto abaixo iremos falar especificamente sobre o Azure Data Lake, que é uma implementação de Data Lake baseado em tecnologia Microsoft (Azure)
O Azure inclui todos os recursos necessários para que seja mais fácil para desenvolvedores, cientistas de dados e analistas armazenar dados de qualquer tamanho, forma ou velocidade, bem como realizar todo tipo de processamento e análise em diferentes plataformas e linguagens. Ele remove as complexidades relacionadas a ingerir e armazenar todos os seus dados, enquanto acelera a execução de análises em lote, streaming e interativas.
Em linhas gerais, o Azure Data Lake trabalha com investimentos existentes em TI para oferecer identidade, gerenciamento e segurança para que haja um controle e um gerenciamento de dados simplificados. Ele também tem integração direta com repositórios operacionais e data warehouses, de modo que você pode ampliar aplicativos de dados atuais. Nós partimos de nossa experiência de trabalho com clientes empresariais e de execução de algumas das análises e processamentos de maior escala para produtos da Microsoft como Office 365, Xbox Live, Azure, Windows, Bing e Skype.
Em resumo, o Azure Data Lake soluciona muitos dos desafios de produtividade e escalabilidade que o impedem de maximizar o valor de seus ativos de dados com um serviço que está pronto para atender as suas necessidades comerciais atuais e futuras.
Maior facilidade para análises em lote, em tempo real e interativas
- Armazene e analise dados de qualquer tipo e tamanho
- Desenvolvimento mais rápido, depuração e otimização com mais inteligência
- Explore, de maneira interativa, padrões em seus dados
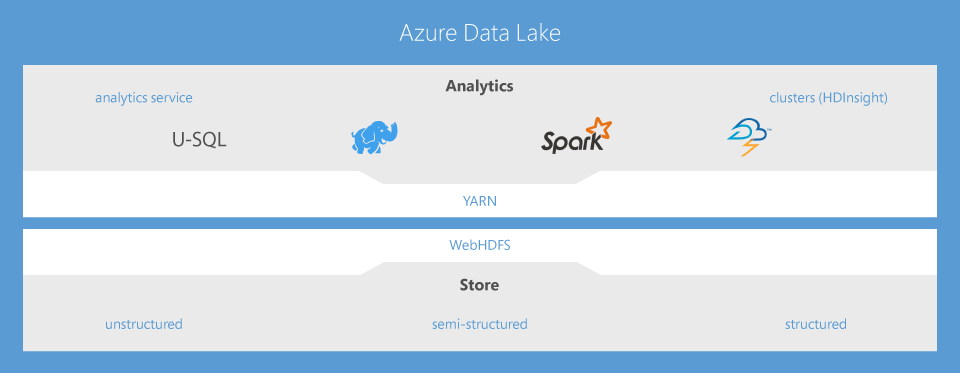
- Sem curva de aprendizado — use U-SQL, Apache Spark, Hive, HBase e Storm
- Gerenciamento e suporte garantidos com SLA de nível empresarial
- É dimensionado dinamicamente de acordo com as prioridades dos seus negócios
- Segurança de nível empresarial com o Active Directory do Azure
- Integrado ao YARN, projetado para a nuvem
Apresentando visualização do nosso novo serviço de análise distribuído
O serviço de análise Data Lake é um novo serviço de análise distribuído criado no Apache YARN que dimensiona dinamicamente, de modo que você pode se concentrar em suas metas de negócios e não na infraestrutura distribuída. Em vez de implantar, configurar e ajustar hardware, você escreve consultas para transformar seus dados e extrair informações importantes. O serviço de análise é capaz de realizar trabalhos de qualquer instantaneamente, simplesmente configurando a potência de que você precisará. Você só paga pelo trabalho quando ele está em execução, o que o torna econômico. O serviço de análise dá suporte para o Active Directory do Azure, permitindo que você simplesmente gerencie o acesso e as funções de maneira integrada com seu sistema de identidade local. Ele também inclui U-SQL, uma linguagem que unifica os benefícios do SQL com a capacidade expressiva do código do usuário. O tempo de execução distribuído escalonável do U-SQL permite que você analise de forma eficiente dados no repositório e em servidores SQL no Azure, Banco de Dados SQL do Azure e SQL Data Warehouse do Azure.
Clusters do Apache Hadoop, Spark, HBase e Storm gerenciados pelo HDInsight
Na estrutura do Azure Data Lake, ele oferece clusters Apache Hadoop®, Spark, HBase e Storm totalmente gerenciados e com suporte completo. Você pode começar a trabalhar rapidamente com qualquer uma dessas cargas de trabalho com poucos cliques e dentro de alguns minutos, sem precisar comprar hardware ou contratar uma equipe de operações especiais normalmente associada à infraestrutura de Big Data. Você tem a opção de executar Linux ou Windows com a Plataforma de Dados Hortonworks Hadoop, facilitando a transferência de código e projetos para a nuvem. Por fim, o rico ecossistema de aplicativos baseados no Apache Hadoop oferece segurança, governança, preparação de dados e análise avançada, permitindo que você aproveite ao máximo seus dados mais rapidamente. Com o Data Lake, o Hadoop fica mais fácil.
Apresentando a visualização do nosso repositório
O Data Lake oferece um repositório único no qual você pode capturar dados de qualquer tamanho, tipo e velocidade de maneira simples, sem forçar alterações em seu aplicativo em decorrência da dimensão dos dados. No repositório, os dados podem ser compartilhados para colaboração com segurança de nível empresarial. Ele também foi desenvolvido para fornecer análises e processamento de alto desempenho de ferramentas e aplicativos HDFS, incluindo suporte para cargas de trabalho de baixa latência. Por exemplo, o repositório pode ingerir dados em tempo real de sensores e dispositivos para soluções de IoT ou de sites de compra online, sem restrições ou limites fixos quanto ao tamanho do arquivo ou da conta, diferente das ofertas no mercado atualmente
Use as habilidades que você tem para desenvolver com mais rapidez e otimizar seu código de forma mais inteligente
Pode ser difícil encontrar as ferramentas certas para elaborar e ajustar suas consultas de Big Data. O Data Lake facilita esse processo através da ampla integração com o Visual Studio, para que você possa usar ferramentas com as quais já está familiarizado para executar, depurar e ajustar códigos. As visualizações de trabalhos do U-SQL, do Apache Hive e do Apache Storm permitem ver como o código é executado em escala, bem como identificar afunilamentos de desempenho e otimizações de custos, o que facilita o ajuste das consultas. Engenheiros de dados, DBAs e arquitetos de dados podem usar habilidades existentes, como SQL, Apache Hadoop, Apache Spark e .NET para serem produtivos desde o primeiro dia. Cientistas e analistas de dados podem usar uma rica experiência de bloco de anotações com tecnologia Apache Spark ou da ferramenta de visualização preferida deles, como Power BI, Tableau ou Qlik, para fazer análises interativas de todos os dados.
Integração total com seus investimentos de TI existentes
Um dos principais desafios do Big Data é a integração com os investimentos de TI existentes. Nós lidamos com isso garantindo que o Data Lake possa utilizar seus investimentos de TI existentes para identidade, gerenciamento e segurança e data warehouse, simplificando o controle de dados e facilitando a ampliação de seus aplicativos de dados. Pronto para ser utilizado, o Data Lake integra-se ao Active Directory para o gerenciamento de usuários e permissões, e inclui ferramentas programáticas e baseadas na web para realizar o gerenciamento e o monitoramento. O Data Lake também é uma parte fundamental da Cortana Analytics Suite, o que significa que ele funciona com o Azure SQL Data Warehouse, o Power BI e o Data Factory formando uma plataforma completa de análise avançada e Big Data na nuvem que ajuda você em todos os estágios, desde a preparação dos dados à realização de análises interativas em conjuntos de dados de grande escala. Além disso, como o Data Lake está inserido no Azure, você pode conectar-se a qualquer dado gerado pelos aplicativos ou consumido pelos dispositivos nos cenários de IoT (Internet das Coisas).
Armazene e analise dados de qualquer tamanho
O Data Lake foi projetado desde o início para proporcionar escala e desempenho na nuvem. Com alguns cliques, você pode provisionar qualquer quantidade de recursos para realizar análises em terabytes ou até mesmo exabytes de dados. O repositório no Data Lake não tem limites fixos quanto ao tamanho do arquivo ou da conta e oferece uma enorme produtividade para aumentar o desempenho analítico. Isso quer dizer que você não precisa reescrever os códigos conforme o aumento ou a diminuição do tamanho dos dados armazenados ou da quantidade de computação usada. Isso permite que você se concentre na lógica dos seus negócios e não no processamento e armazenamento de grandes conjuntos de dados. O Data Lake também elimina a complexidade que geralmente está associada ao Big Data na nuvem, o que garante que ele atenderá às suas necessidades comerciais atuais e futuras. Na Microsoft, a mesma tecnologia está sendo utilizada por mais de 10.000 desenvolvedores para executar análises de exabytes de dados para o Microsoft Bing, o Office e o Xbox Live.
Financeiramente viável e econômico
O Data Lake é uma solução econômica para executar cargas de trabalho de Big Data. Você pode optar por clusters sob demanda ou um modelo de pagamento por trabalho quando os dados forem processados. Nos dois casos, não é necessário adquirir hardware nem contratar licenças ou contratos de suporte específicos para serviços. É possível ampliar ou reduzir a escala do sistema de acordo com suas necessidades comerciais, o que quer dizer que você nunca paga mais que o necessário. Ele também permite dimensionar de maneira independente o armazenamento e a computação, o que proporciona mais flexibilidade econômica em comparação com as soluções de Big Data tradicionais. Além disso, ele minimiza a necessidade de contratar equipes operacionais especializadas, que normalmente associadas a execução de infraestruturas de Big Data. O Data Lake minimiza seus custos e maximiza o retorno sobre seu investimento em dados.
Nível empresarial
O Data Lake tem suporte e é completamente gerenciado pela Microsoft, que também fornece um SLA de nível empresarial e suporte com disponibilidade geral. Você pode entrar em contato conosco por meio do atendimento ao cliente – disponível 24 horas por dia, 7 dias por semana – para solucionar qualquer problema que surja na solução de Big Data. Nossa equipe monitora a sua implantação para você, garantindo assim a sua execução contínua. Isso que garante que você esteja pronto para atender às demandas de suas implantações críticas.
Compile soluções do Data Lake usando essas soluções avançadas
DATA LAKE AWS
No Amazon Web Services (AWS) existe um ambiente para DataLake chamado “Data Lake Formation” que é uma série de ferramentas que pode ser dedicada a construção do seu ambiente analítico de dados em nuvem
DATA LAKE GOOGLE
O Google Cloud Plataform (GCP) também oferece uma diversidade de ferramentas para montagem do DataLake.